
为AI和HPC研发和应用赋能
如今,谈及人工智能几乎人人皆知,它几乎涵盖了所有IT领域的层次,人们从不同层次和角度都会对人工智能有自己的理解和阐述。
在正式开始介绍公共科学计算之前,我们首先需要把谈论的技术领域和范围圈定好,因为如果要在特定层面上谈论人工智能,就要先搞清楚人工智能的分类以及分类中的技术定义。
认识和了解人工智能
今天,AI(人工智能)从原来的狭义定义逐渐扩展到了广义的定义,这里从技术上明确以下狭义的AI范畴(如图1)。
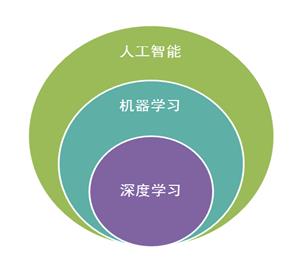
图1 人工智能、机器学习、深度学习的关系
从技术范畴上来看,机器学习是人工智能的子类,而深度学习是机器学习的子类。机器学习与深度学习的相同之处是都要通过一定的算法对大量数据进行复杂的数学运算,这个过程称为训练,目的是对一个业务问题的未来结果有高精确度的预测,并放到实际的推理环境中应用。
机器学习比深度学习出现得更早,它一般是指算法工程师利用 LR、SVM、感知机等若干个模型和大量数学算法解决一个个实际问题的过程,工作重点主要是在特征工程方面。在很多情况下,特征的构造方法复杂多变,是否有用往往取决于问题本身、数据样本、模型以及运气,因此很多尝试都不能在实际工作中发挥作用。
机器学习的典型特征可以总结为利用简单模型描述复杂特征。简单模型说的是算法,以 LR(逻辑回归算法)为例,其算法本身并不复杂,参数和表达能力基本呈现某种线性关系,非常易于理解;复杂特征则是指特征工程方面不断尝试使用各种技巧构造的特征,这部分特征的构造方式可能会利用各种数学计算,比如窗口滑动、离散化、归一化、开方、平方、笛卡尔积、多重笛卡尔积等,这些计算都需要底层设备具备很高的计算能力。
而在深度学习概念提出以后,大家发现,通过深度神经网络可以进行一定程度的特征描述,例如通过 CNN 提取图像特征(Feature),并在此基础上进行分类的方法,就能够解决线形不可分问题,并且省却大量用于特征提取的人力。
但即便如此,由于不同业务的大数据自身内在结构的差异,在个性化推荐、精准营销、多维分析等领域,深度学习并没有优势。另外,深度学习也带来了模型复杂、不可解释的问题,需要算法工程师在神经网络结构设计方面花大量的心思提升效果。其典型特征概括起来就是,通过简单特征加上复杂模型来解决特征提取问题,并进一步提升预测精度。
公共科学计算的生态、关键技术和核心诉求
在了解了机器学习和深度学习之后,我们再来看AI和HPC(高性能计算)。我们发现,AI和HPC领域的科研和应用对于底层基础设施有两个共同的技术需求:一是相关领域的科研和应用都要经过复杂的数学计算,因此需要很高的计算性能;二是要采用并行计算的模式提高计算效率。为此,研发人员需要采购大量高性能配置的服务器、高可用的存储和高速网络组成集群系统,并在这个集群系统之上,加装大量的匹配硬件基础设施的Runtime和Programming Model工具及软件,包括操作系统、适配高性能硬件的各种驱动、集群部署和监控软件、编码语言和编译环境、并行计算通讯库、数学库、资源调度软件、计算框架、参考模型等等。
其中,底层的芯片、服务器、存储和网络层面虽然有很多的共同性,但是上层的Runtime和Programming Model,以及解决具体问题的应用层面仍有不同,因此资源的整合是个问题。
通过对包括企业和高校科研机构在内的很多客户的调研,我们发现,他们在解决具体业务问题的过程中,很多都涉及到HPC和AI应用。其中,很多客户就由于上层Runtime和Programming Model以及开发和应用等方面的诸多差异,底层基础设施无法得到资源共享,不仅无法实现多租户的使用,对于应用部署和开发环境部署无法实现自动化。这就造成了很多开发者不得不搭建适合自己的开发和应用环境。更重要的是,业务开发和应用一般要求规模较大且高性能的IT资源支持,但由于很多高性能的IT资源在单一业务开发和应用的空闲时间无法及时给另外的项目组使用,因此常常造成很大的资源浪费,这触发了专业私有云的需求。核心的诉求是要在一个高性能基础设施平台上支持多种高性能业务的开发和应用,同时让开发者能够自动化部署自己的应用环境。
根据上述分析,可以看到,资源共享平台不仅要解决关于TFLOPS以及EFLOPS级别的LINPAC值的硬件环境问题,更关键的是要支持有复杂数学计算和高性能并行计算的软件环境和应用,通过配合硬件环境从而提供专业完整的系统。因此,在落地实现中将涉及大量数学计算和并行计算的开发及应用环境的相关技术。其核心是围绕Runtime和Programming Model的技术问题,在一个平台实现HPC和AI的融合,这是资源共享的前提。
也正因如此,业界的公有云公司纷纷推出了高性能计算云。但与私有云平台相比,由于二者的定位、核心出发点及核心关注的技术领域有所不同,适用的场景和市场也有差异。从架构上看公有云更关注自动化和简单性,它面向的是大众用户的需求;而私有云则兼顾提供自动化和专业设计的功能,这是公有云架构和模式做不到的。
此外,针对高性能业务研发和应用的公共科学计算平台,必须优先保证所管理的IT资源的高性能、高可靠和高容错。在此基础上,企业才能进行资源的灵活调配、弹性扩展和自动化服务目录等需求的实现,这也正是采用容器而非虚拟化技术的原因之一。据测试,采用容器进行多租户资源隔离对于计算性能的损耗在5%左右,这是可以接受的。另外,容器镜像的封装量远远少于虚拟机镜像,其范围一般在几兆到几十兆字节之间,因为它不负责封装操作系统,因此对于镜像在服务器之间的流转和启动,以及高性能业务的开发和应用,复杂的Runtime和Programming Model环境和配置更具优势。当然,对于公共科学计算平台而言,容器只是能够实现多租户资源隔离和使用权限的工具之一,容器集群的编排工具则可以采用有广泛使用基础和活跃社区的Kubernetes。
对于企业和高教的高性能研发和应用团队来说,由于属于专业领域,其开发人员和应用使用人员不仅关注专业操控的自由度,对自动化程度有很大需求,同时还希望在内部实现资源共享,因此更适合采用专业架构建设一个专业的公共科学计算的平台。一创为AI和HPC研发和应用赋能
一创一直把公共科学计算作为重点研究和开发的技术领域,研究其中相关的融合技术,打造公共科学计算生态,提供公共科学计算整体解决方案和平台,赋能客户的人工智能高性能业务的研发和应用。
一创的整体解决方案包括了底层高性能的服务器、高可用的并行存储系统、高速网络连接、高性能的公共科学计算IT资源池建设、专业的私有公共科学计算PaaS平台,并利用容器技术在不影响性能的前提下实现资源的弹性扩展。同时,为了支持人工智能落地,平台通过AIOS实现了机器学习和深度学习中的很多特殊功能需求,提供专业开发人员的自动化和对技术服务掌控能力,包括为多开发项目组提供GPU开发资源的自动化交互流程、训练队列、推理发布,以及为该过程中图形化提供可参考的神经网络模型和算法模板。
此外,解决方案还提供丰富的软件工具库和私有容器镜像库,用户可以很方便地将这些工具拖拽安装到自己的容器环境中,并实时加载需要的软件工具和数学库,以辅助开发自己的容器环境。这大大简化了专业开发者的安装过程,帮助他们快速搭建完整的开发和应用环境,减少更多依赖于环境的配置工作。同时,也能在同一物理集群中实现各种不同Runtime和Programming Model环境的快速加载和环境配置,并且能快速卸载,干净地释放资源,满足多租户需求。
再者,针对AI深度学习训练过程中复杂不可解释的参数选配,为了减少尝试次数、浪费资源和时间,一创的公共计算解决方案也提供丰富的超参算法支持,支持Random Search、TPE(Tree-based Parzen Esitmator)以及Bayesian等超参搜索算法,充分发挥集群计算能力,通过多任务并发搜索在不同任务间分享不同的搜索结果,最终以改进效率为目标,做到搜索效果与搜索代价的平衡,提供蒙特卡洛树搜索 + 深度学习网络功能,解决搜索空间过大的问题,并对搜索结果进行学习。以下是一创公共科学计算解决方案的架构设计(如图2):
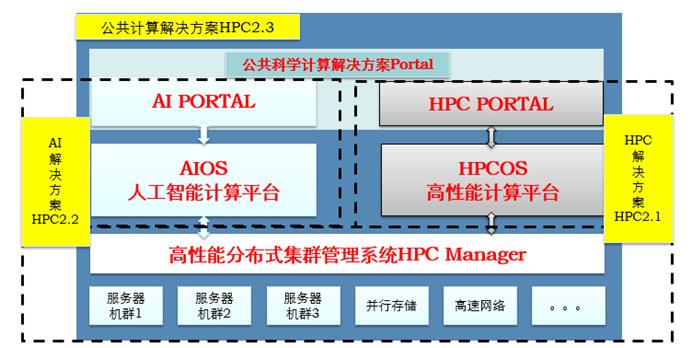
图2 一创公共科学计算解决方案架构
总体而言,一创公共科学计算解决方案将为客户建设完整的公共科学计算平台,实现多业务项目组的高性能IT资源池共享,实现HPC、AI中通用IT系统研发和应用的融合,实现与原有企业云平台的上层对接。同时,作为企业云的VDC存在,在同一接口上提供HPC、AI的服务目录,为深化企业或者高教院校的科研信息化服务,为AI高性能业务应用赋能。
